[왕초보 웹크롤링 무작정 따라하기] 쥬피터노트북 라이브러리 설치, requests, BeatifulSoup, html 불러오기
#02 request와 BeatifulSoup 사용해서 html 불러오기
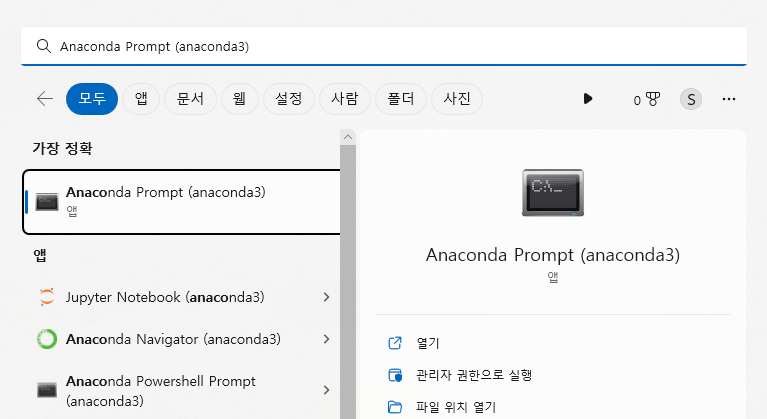
쥬피터노트북 라이브러리 설치하기 (바로가기 Click)
01. 패키지 설치하기
pip install requests
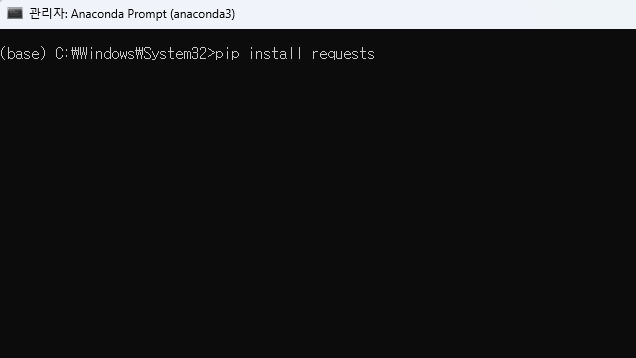
pip install BeautifulSoup4정적 페이지를 크롤링하기 위해서는 requests와 BeatifulSoup 라이브러리가 필요하다. 주피터 노트북에서 라이브러리는 'Anaconda Prompt (anaconda 3)'에서 설치할 수 있다. 'Anaconda Prompt (anaconda 3)'는 바탕화면 작업표시줄에서 검색하면 쉽게 찾을 수 있다. 'Anaconda Prompt (anaconda 3)'을 실행시키면 나오는 검은 화면에 pip install requests적고 엔터를 치면 requests 라이브러리의 설치된다. 마찬가지로 pip install BeautifulSoup4로 BeautifulSoup 라이브러리를 설치해 주자.
02. 웹에서 html 불러오기
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.google.com/")
soup = BeautifulSoup(response.text, 'html.parser')
print(response)
print(response.text)
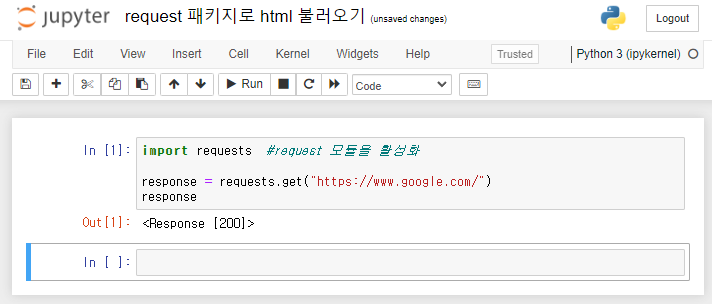
print(soup)쥬피터노트북에서 라이브러리를 사용하기 위해서는 먼저 필요한 라이브러리를 import 시켜줘야 한다. 코드를 적는 셀 가장 처음에 import request와 from bs4 import BeautifulSoup를 적어주면 된다. 우리는 requests.get()의 괄호 안에
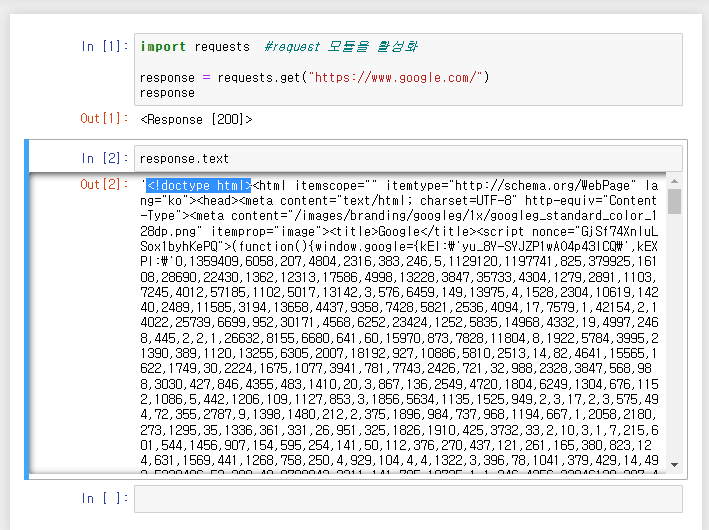
"url"을 입력하여 html을 가져올 수 있다. 테스트로 크롬브라우저의 첫 화면의 html을 불러와보도록 하자. 가져온 html를 response로 정의하고 print()해보면 <Response [200]>라는 값이 출력되는 것을 볼 수 있고, response.text를 print()해보면 <!doctype html>로 시작하는 html 문서를 확인할 수 있다. 이 html에 웹페이지에서 나타나는 정보가 담겨 있는 것이다.
html이 정상적으로 불러와졌지만 html 문서를 눈으로 파악하고 데이터를 추출하기 위해서는 BeautifulSoup을 통한 파싱이 필요하다. 파싱이란 웹에서 불러온 html을 파이썬으로 처리할 수 있도록 구조화하는 것이다. BeautifulSoup(response.text, 'html.parser')으로 파싱한 html을 출력해보면 response.text와 비슷하지만, 파이썬으로 html문서를 처리할 수 있게 된 것이다.
▼html에서 텍스트/숫자/url 추출하기▼
'데이터 스킬업 > 웹크롤링' 카테고리의 다른 글
| [파이썬: 웹크롤링] #05 웹에서 텍스트 정보 뽑아내기 with BeautifulSoup, select, get_text (feat. 중복 경로 확인하기) (0) | 2023.03.01 |
|---|---|
| [파이썬: 웹크롤링] #03 html에서 데이터 출력하기 with BeautifulSoup (0) | 2023.03.01 |
| [파이썬: 웹크롤링] #01 웹크롤링 입문! 정적/동적 페이지에 대하여 (0) | 2023.02.28 |
| [파이썬: 웹크롤링] #00 웹크롤링 사전준비, 파이썬/쥬피터노트북/크롬브라우저 설치부터 실행까지 (1) | 2023.02.28 |
| [파이썬:웹크롤링] #15 셀레니움 크롤링 반복문 with for문 & range (4) | 2022.06.23 |
댓글