[왕초보 웹크롤링 따라하기] 웹크롤링, 파이썬, 데이터 추출, 엑셀표만들기, 리스트업, 예제
#11 쇼핑몰 주문수/별점/댓글 리스트업(예제)
이제 웹사이트의 텍스트 정도는 쉽게 뽑아내서 정리할 수 있을 것만 같다. 익힌 것들을 어디에 써볼 수 있을까?
도전과제
온라인에서 판매되는 LG전자 스타일러 제품 중 리뷰수가 가장 많은 제품의 제품정보(제품명, 등록일, 최저/최고 가격), 평점, 평점 별 리뷰 수를 엑셀 표로 정리하시오. (네이버쇼핑 LG전자 페이지 : https://brand.naver.com/lge)
- 가이드 -
1. 데이터가 있는 페이지 url 확인
2. 필요한 데이터 선정 및 html 확인
3. 코드 작성
해결 과정 (아래 더보기를 누르면 풀이가 나와요!)
1. 데이터가 있는 페이지 url 확인
먼저 원하는 정보가 있는 웹사이트를 찾아야 한다. 원하는 데이터를 찾기 위해 페이지에서 제공하는 검색기능을 사용한다.
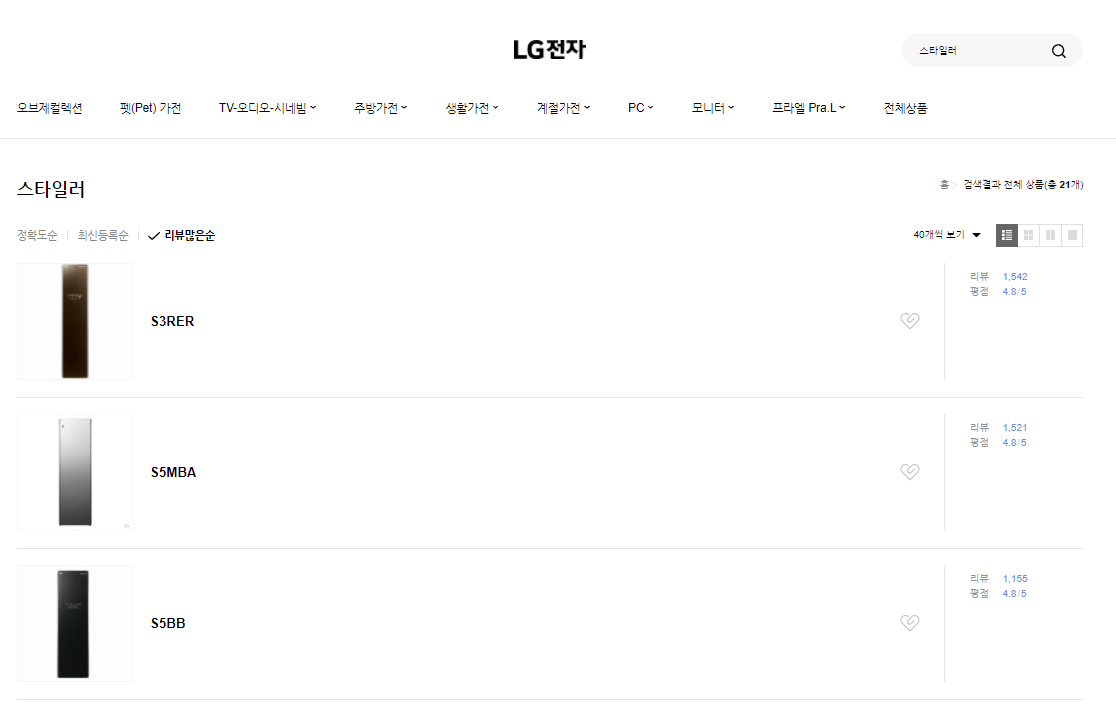
2. 필요한 데이터 선정 및 html 확인
각 제품을 들어가 상세페이지를 확인한다.

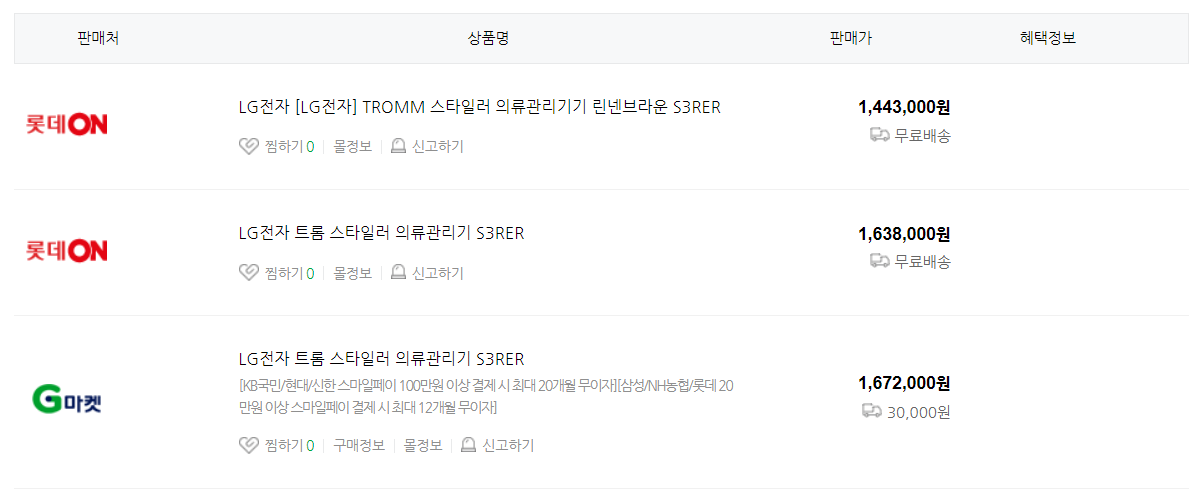
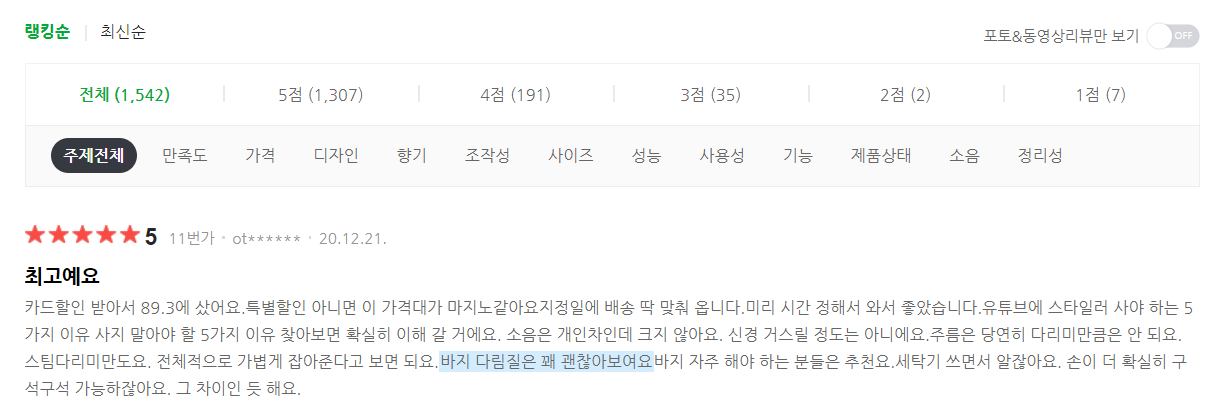
추출하고자 하는 제품정보(제품명, 등록일, 최저/최고 가격), 평점, 평점 별 리뷰수를 확인할 수 있다. 해당 데이터들의 html과 중복여부를 확인하자.
▼ 중복 검사/확인하는 방법글
[파이썬 : 웹크롤링] #05 html 태그 중복, 검사와 확인
[왕초보 웹크롤링 따라하기] html 태그 중복 검사, 중복 태그 확인, html 개발자 도구 업무지옥을 탈출한 건에 대하여(feat.업무자동화) #05 html 태그 중복, 검사와 확인 웹크롤링을 하기 위해서 h
charimlab.tistory.com
제품명
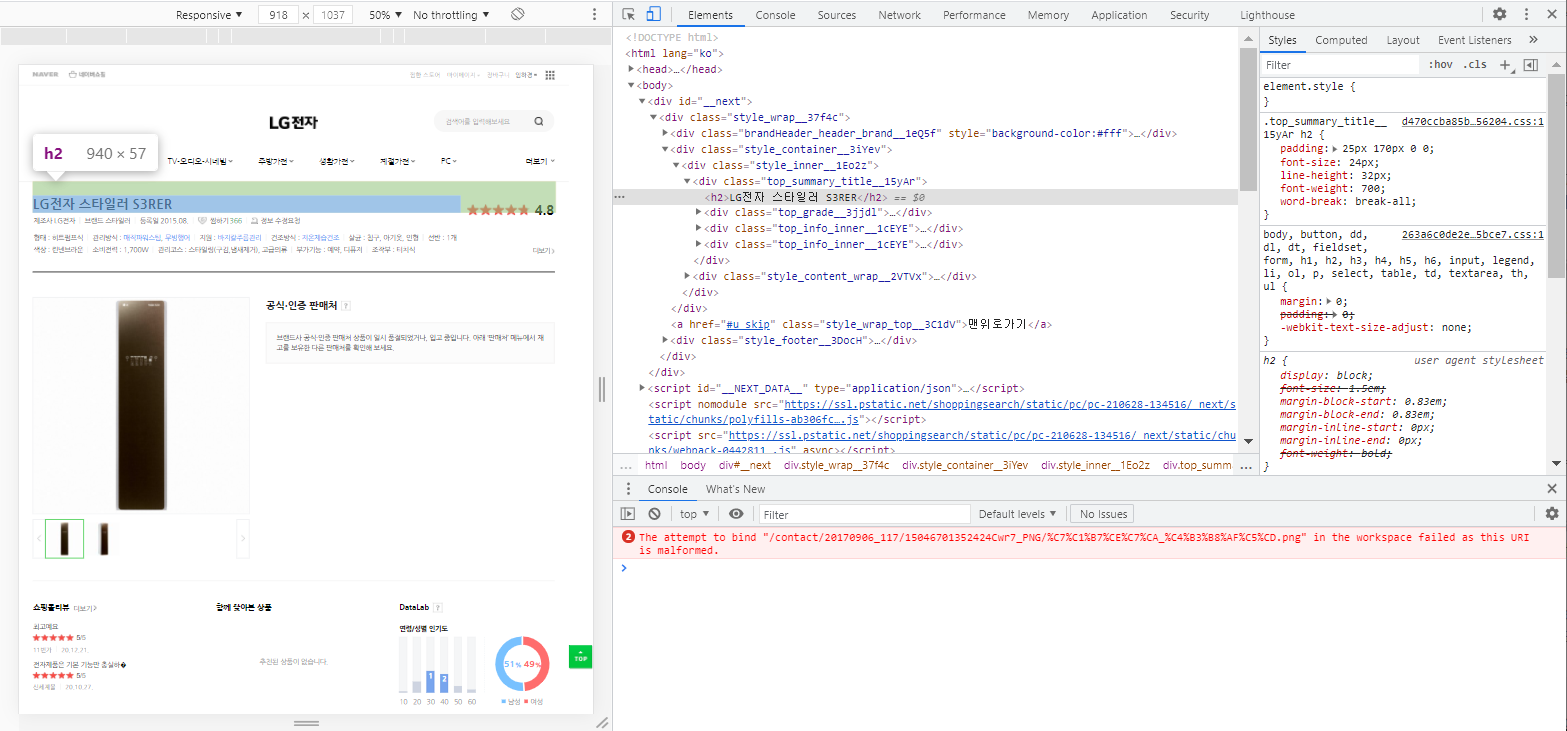
등록일
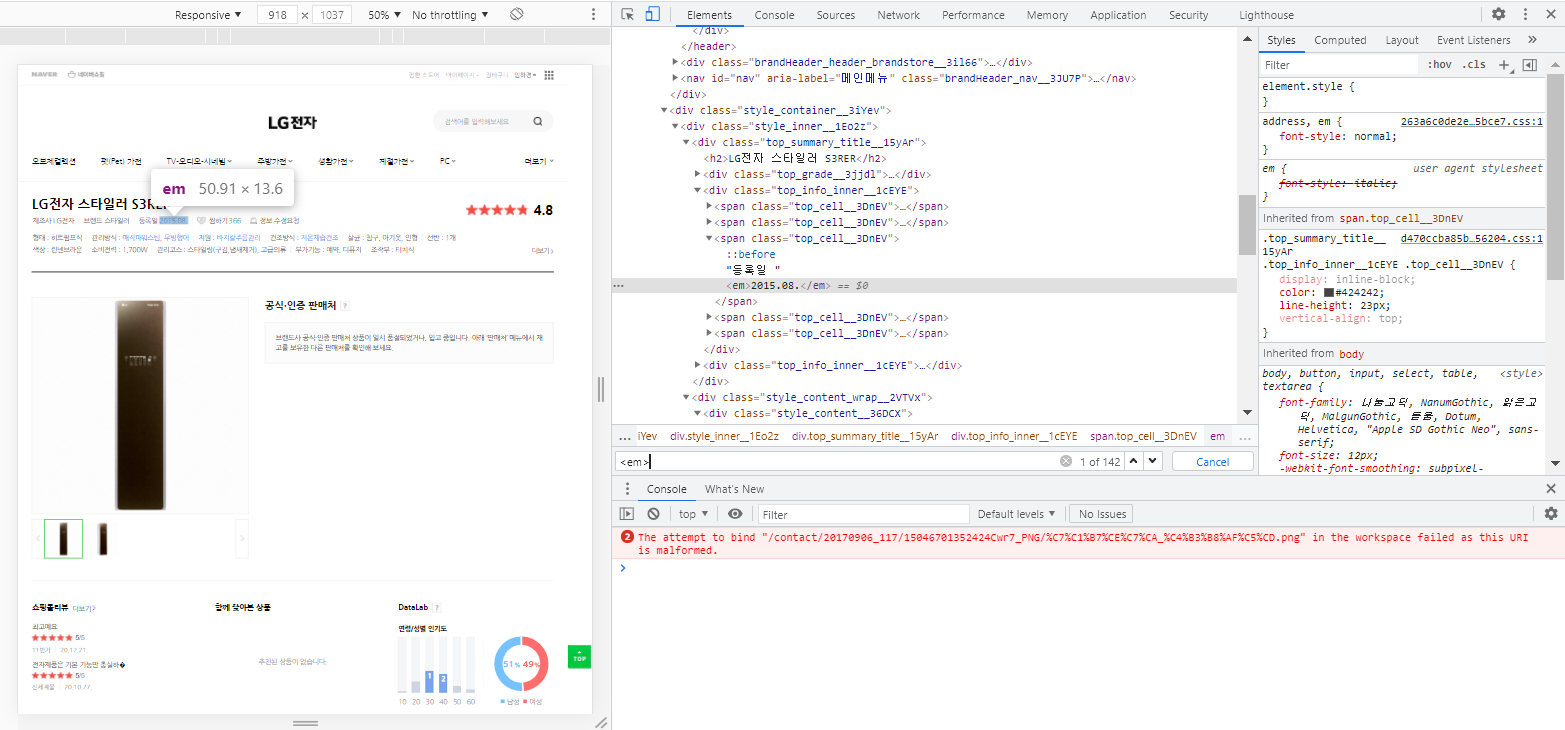
평점
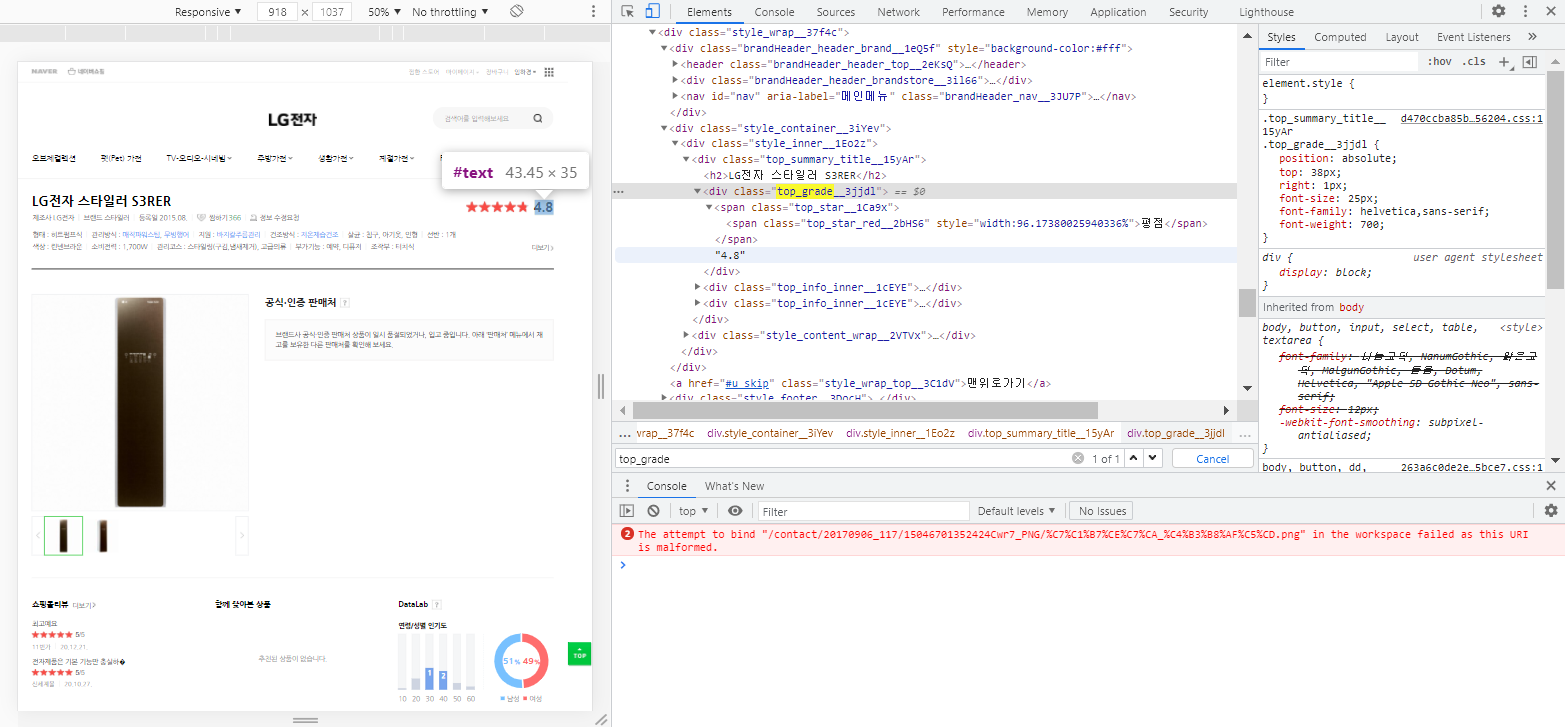
최저/최고 판매가
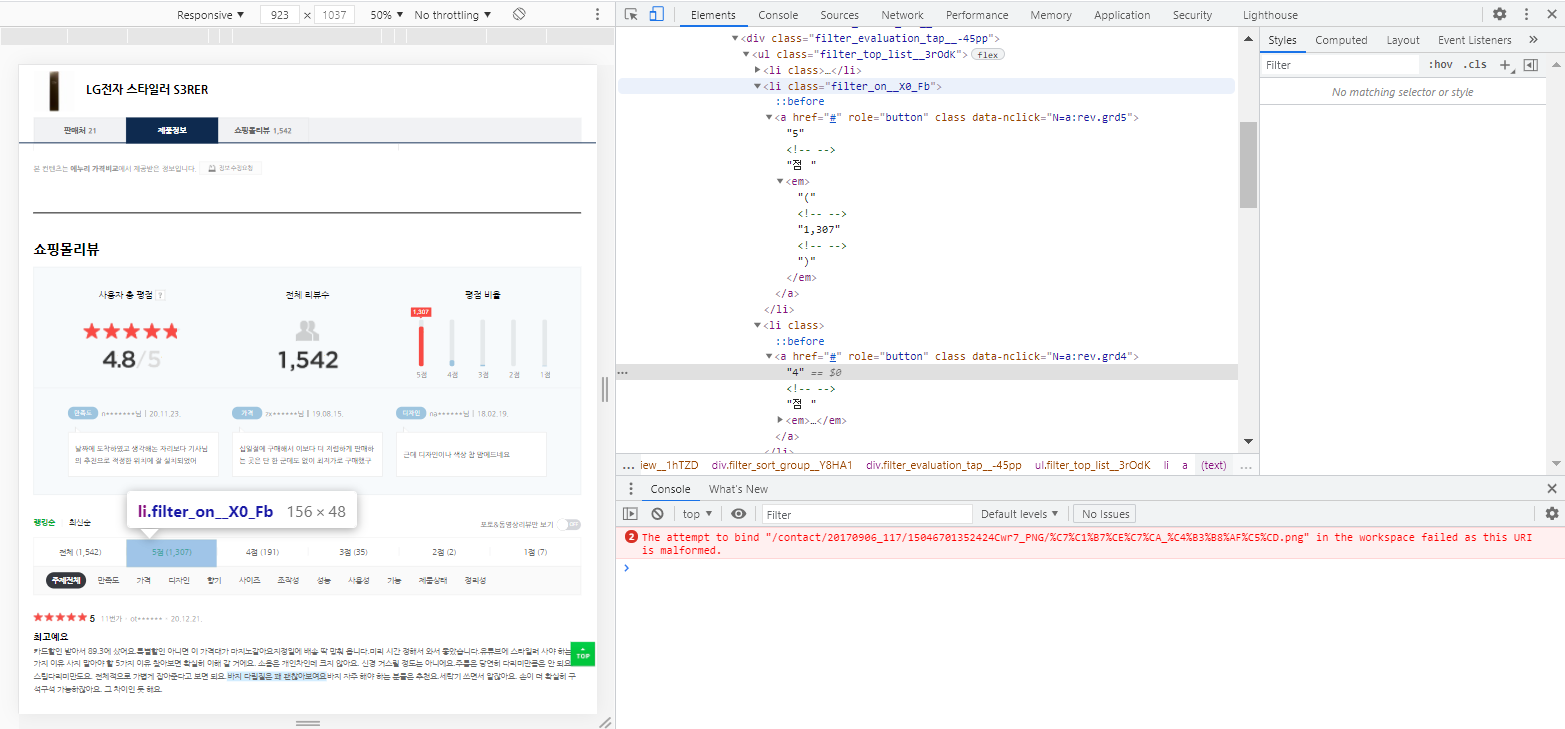
평점 별 리뷰 수
여기까지 확인한 html 선택자는 아래와 같다.
| 데이터 | html 선택자 | |
| 제품명 | <h2> 중 첫번 째 값 |
|
| 등록일 | <span class="top_cell__3DnEV"> 아래 <em> 중 3번 째 값 |
|
| 평점 | <div.top_grade__3jjd1> 아래 <em> | |
| 최저/최고 판매가 | <a.productlist_value_XRe6h > 아래 <em> *해당 선택자의 처음과 마지막 값을 추출해 줘야한다. |
|
| 평점 별 리뷰 수 | 5점 | <ul.filter_top_list__3rodk> 아래 <em> 중 2번째 값 |
| 4점 | <ul.filter_top_list__3rodk> 아래 <em> 중 3번째 값 |
|
| 3점 | <ul.filter_top_list__3rodk> 아래 <em> 중 4번째 값 |
|
| 2점 | <ul.filter_top_list__3rodk> 아래 <em> 중 5번째 값 |
|
| 1점 | <ul.filter_top_list__3rodk> 아래 <em> 중 6번째 값 |
|
*경로는 홈페이지의 보안을 위해 주기적으로 변경될 수 있으니, 항상 확인해야 함.
3. 코드 작성
엑셀표로 만들기 위해 column과 row값을 먼저 생각하고 코드를 짜야한다.
| 제품명 | 평점 | 5점 개수 | 4점 개수 | 3점 개수 | 2점 개수 | 1점 개수 | 최저가 | 최고가 | 등록일 |
이런 형태로 표를 만들겠다고 생각하면 columns = [ '제품명', '평점', '5점 개수', '4점 개수', '3점 개수', '2점 개수', '1점 개수', '최저가', '최고가', '등록일' ] 로 설정할 수 있다. 이제 본격적으로 코드를 작성하자.
먼저 requests와 BeautifulSoup 모듈을 활성화 시키고 웹의 html을 불러와준다.
# 라이브러리 활성화
import requests
from bs4 import BeautifulSoup
# html 불러오기
web_site = requests.get("~")
web_html = BeautifulSoup(web_site.text, 'html.parser')
html을 불러왔으니 앞서 확인한 <태그>와 선택자를 .select()와 .find() 메소드와 리스트 슬라이싱 [0:0]을 통해
데이터를 추출해야 한다. .select()와 .find() 무엇을 사용하든지 상관없다.
▼ .select() .find() 메소드 사용법
[파이썬: 웹크롤링] #06 html/CSS 선택자 선택하기 with Select & Find
[왕초보 웹크롤링 무작정 따라하기] 파이썬 반복문(for문/폴문), .select(), .find(), html 추출, 태그 추출, 선택자 추출, 필터링. 업무지옥을 탈출한 건에 대하여(feat.업무자동화) #06 html/CSS 선택자 선
charimlab.tistory.com
중간중간 print()를 사용해 데이터 값을 출력해 정상적으로 추출되는지 확인해 보자.
# .select_one()메소드로 <h2> 중 첫번째만 선택.
product_name = web_html.select_one('h2').get_text()
# .select()로 중복 추출되는 [ 제조사, 브랜드, 등록일 ]를 슬라이싱하여 3번째(인덱스 2)값만 선택
upload_data = web_html.select('.top_cell__3DnEV em')[2].get_text()
# .find()로 추출되는 text(=평점4.8)을 숫자만 추출하기 위해 3번째(인덱스2)~5번째(인덱스6)을 추출
average_grade = web_html.find(class_="top_grade__3jjdl").get_text()[2:5]
# 중복추출 되는 값 중 첫번째와 마지막을 각각 추출
low_price = web_html.select('.productList_price__2FKhU em')[0].get_text()
high_price = web_html.select('.productList_price__2FKhU em')[-1].get_text()
# 중복되는 추출 값 중 2~6번째 값을 각각 선택하여, 숫자만 추출하기 위해 2번째~마지막 전까지의 값 추출
five_point = web_html.select('.filter_top_list__3rOdK em')[1].get_text()[1:-1]
four_point = web_html.select('.filter_top_list__3rOdK em')[2].get_text()[1:-1]
three_point = web_html.select('.filter_top_list__3rOdK em')[3].get_text()[1:-1]
two_point = web_html.select('.filter_top_list__3rOdK em')[4].get_text()[1:-1]
one_point = web_html.select('.filter_top_list__3rOdK em')[5].get_text()[1:-1]
데이터가 정상적으로 추출된 것을 확인 했으니 이제 엑셀에 데이터를 넣어보도록 하자.
▼ 파이썬으로 엑셀 표 만들기
[ep01: 웹크롤링] #7 데이터의 시각화, 엑셀 만들기! with 파이썬
Teaser Copy. 퍼포먼스 마케팅, 그로스해킹, 데이터 측정을 위한 웹 데이터 수집. 파이썬으로 웹 데이터 수집을 자동으로! [왕초보 웹크롤링 따라하기] 데이터 시각화, exel 변환, 파이썬 도표 만들기
charimlab.tistory.com
라이브러리 openpylx를 활성화 시키고 .Workbook()으로 엑셀파일을 만들어 주고 .create_sheet('~')로 시트를 지정해 준다. 그리고 앞서 생각해 두었던 표의 column값이 되어줄 [리스트]를 적어주자.
| 제품명 | 평점 | 5점 개수 | 4점 개수 | 3점 개수 | 2점 개수 | 1점 개수 | 최저가 | 최고가 | 등록일 |
columns = [ '제품명', '평점', '5점 개수', '4점 개수', '3점 개수', '2점 개수', '1점 개수', '최저가', '최고가', '등록일' ] 로 설정할 수 있다.
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook # openpyxl 모듈 활성화
#컬럼 값을 지정하여 엑셀시트 생성
wb = Workbook(write_only=True)
ws = wb.create_sheet('LG 스타일리스트 온라인 반응')
ws.append([ '제품명', '평점', '5점 개수', '4점 개수', '3점 개수', '2점 개수', '1점 개수', '최저가', '최고가', '등록일' ])
web_site = requests.get("~")
web_html = BeautifulSoup(web_site.text, 'html.parser')
product_name = web_html.select_one('h2').get_text()
upload_data = web_html.select('.top_cell__3DnEV em')[2].get_text()
average_grade = web_html.find(class_="top_grade__3jjdl").get_text()[2:5]
low_price = web_html.select('.productList_price__2FKhU em')[0].get_text()
high_price = web_html.select('.productList_price__2FKhU em')[-1].get_text()
five_point = web_html.select('.filter_top_list__3rOdK em')[1].get_text()[1:-1]
four_point = web_html.select('.filter_top_list__3rOdK em')[2].get_text()[1:-1]
three_point = web_html.select('.filter_top_list__3rOdK em')[3].get_text()[1:-1]
two_point = web_html.select('.filter_top_list__3rOdK em')[4].get_text()[1:-1]
one_point = web_html.select('.filter_top_list__3rOdK em')[5].get_text()[1:-1]
마지막으로 추출한 데이터를 엑셀 row값에 넣어서 저장하면 끝!
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook # openpyxl 모듈 활성화
#컬럼 값을 지정하여 엑셀시트 생성
wb = Workbook(write_only=True)
ws = wb.create_sheet('LG 스타일리스트 온라인 반응')
ws.append([ '제품명', '평점', '5점 개수', '4점 개수', '3점 개수', '2점 개수', '1점 개수', '최저가', '최고가', '등록일' ])
web_site = requests.get("~")
web_html = BeautifulSoup(web_site.text, 'html.parser')
product_name = web_html.select_one('h2').get_text()
upload_data = web_html.select('.top_cell__3DnEV em')[2].get_text()
average_grade = web_html.find(class_="top_grade__3jjdl").get_text()[2:5]
low_price = web_html.select('.productList_price__2FKhU em')[0].get_text()
high_price = web_html.select('.productList_price__2FKhU em')[-1].get_text()
five_point = web_html.select('.filter_top_list__3rOdK em')[1].get_text()[1:-1]
four_point = web_html.select('.filter_top_list__3rOdK em')[2].get_text()[1:-1]
three_point = web_html.select('.filter_top_list__3rOdK em')[3].get_text()[1:-1]
two_point = web_html.select('.filter_top_list__3rOdK em')[4].get_text()[1:-1]
one_point = web_html.select('.filter_top_list__3rOdK em')[5].get_text()[1:-1]
# 위에 추출한 데이터 값을 리스트로 묶어 ws에 추가
ws.append([product_name, upload_data, average_grade, low_price, high_price, five_point, four_point, three_point, two_point, one_point])
# '파일이름.xlsx'로 엑셀 확장자로 저장
wb.save('LG 스타일러 평점.xlsx')
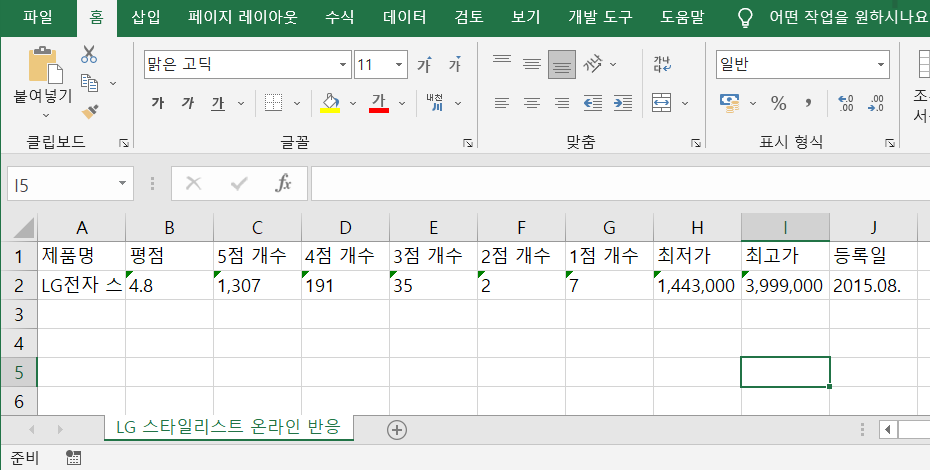
간단한 정보를 리스트업 하는데
너어~~무 오래 걸리고 복잡한 것같다.
하지만 이런 작업을 한번만 해두면
코드 몇줄 추가하는 걸로 자동화가 가능하다.
심화과정
위 과정에 for 반복문을 추가하면 동일한 html 구조라는 전제 하에 수십 수백 페이지의 데이터도 쉽게 추출할 수 있다.
▼전체 코드
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
wb = Workbook(write_only=True)
ws = wb.create_sheet('LG 스타일리스트 온라인 반응')
ws.append([ '제품명', '평점', '5점 개수', '4점 개수', '3점 개수', '2점 개수', '1점 개수', '최저가', '최고가', '등록일' ])
# 데이터를 추출할 url을 리스트로 묶어줌
web_sites=[ "~url~", "~url~", "~url~", "~url~", "~url~", "~url~", "~url~", "~url~", "~url~", "~url~" ]
# for 반복문을 활용해 각 사이트의 데이터를 자동으로 추출
for web in web_sites:
web_site = requests.get(web)
web_html = BeautifulSoup(web_site.text, 'html.parser')
product_name = web_html.select_one('h2').get_text()
upload_data = web_html.select('.top_cell__3DnEV em')[2].get_text()
average_grade = web_html.find(class_="top_grade__3jjdl").get_text()[2:5]
low_price = web_html.select('.productList_price__2FKhU em')[0].get_text()
high_price = web_html.select('.productList_price__2FKhU em')[-1].get_text()
five_point = web_html.select('.filter_top_list__3rOdK em')[1].get_text()[1:-1]
four_point = web_html.select('.filter_top_list__3rOdK em')[2].get_text()[1:-1]
three_point = web_html.select('.filter_top_list__3rOdK em')[3].get_text()[1:-1]
two_point = web_html.select('.filter_top_list__3rOdK em')[4].get_text()[1:-1]
one_point = web_html.select('.filter_top_list__3rOdK em')[5].get_text()[1:-1]
ws.append([product_name, average_grade, five_point, four_point, three_point, two_point, one_point, low_price, high_price, upload_data, ])
wb.save('LG 스타일러 평점 종합.xlsx')기존 코드에서 딱 2줄 더 쓰고 url만 복붙복붙 하면 끝!!
▼다음글 이어보기▼
[ep01:웹크롤링] #11 동적 페이지웹 동작 자동화(Selenium) with 파이썬
Teaser Copy. 퍼포먼스 마케팅, 그로스해킹, 데이터 측정을 위한 웹 데이터 수집. 파이썬으로 웹 데이터 수집을 자동으로! [왕초보 웹크롤링 따라하기] 웹크롤링, 파이썬, 웹자동화, 셀레니움, Seleni
charimlab.tistory.com
'데이터 스킬업 > 웹크롤링' 카테고리의 다른 글
| [파이썬:웹크롤링] #13 인스타그램 로그인하기 with Selenium (1) | 2022.06.12 |
|---|---|
| [파이썬:웹크롤링] #12 동적 웹페이지 크롤링 with Selenium (0) | 2022.06.12 |
| [파이썬:웹크롤링] #10 쥬피터노트북 dataframe 만들기 with Pandas (0) | 2022.06.12 |
| [파이썬: 웹크롤링] #09 리스트로 데이터프레임(DataFrame) 만들기 with Pandas (0) | 2022.06.12 |
| [파이썬: 웹크롤링] #08 데이터의 시각화, 엑셀 만들기! with openpyxl (0) | 2022.06.12 |
댓글