[왕초보 웹크롤링 무작정 따라하기] 웹크롤링, 셀레니움, 동적페이지, 셀레니움 파싱, for반복문
업무지옥을 탈출한 건에 대하여(feat.업무자동화)
#19 인스타그램 웹크롤링 자동화(예제)
동적페이지를 다루기 위한 수련을 모두 마쳤다. 조금 더 난이도를 높여 인스타그램 피드의 게시물 인사이트를 크롤링하고 데이터를 엑셀로 정리해보자.

도전 과제
인스타그램 피드 인사이트에서 '날짜 / 노출 / 좋아요 / 댓글 / 공유 / 프로필방문 / 도달계정 / 팔로우 획득' 수치를 추출하여 엑셀로 저장하시오.
- 가이드 -
1. 셀레니움을 통한 로그인 및 프로필 페이지 도달
2. 스크롤 이동과 상대좌표와 자바스크립트를 활용한 동작 자동화
3. 데이터 추출 및 오류무시 코드 추가
4. 엑셀생성 코드 추가
해결 과정 (아래 '더보기'를 누르면 풀이가 나와요!)
👇👇👇
1. 셀리니움을 통한 로그인 및 프로필 페이지 도달
브라우저를 제어하여 인스타그램에 로그인 하고, 셀레니움 action을 통해 프로필 페이지까지 들어간다.
# 라이브러리 활성화
import time
from openpyxl import Workbook
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#웹 열
dr = webdriver.Chrome()
wait = WebDriverWait(dr, 5)
dr.set_window_size(414, 800)
dr.get('https://www.instagram.com/')
dr.implicitly_wait(2)
#로그인
id_box = dr.find_element_by_css_selector("#loginForm > div > div:nth-child(1) > div > label > input")
password_box = dr.find_element_by_css_selector("#loginForm > div > div:nth-child(2) > div > label > input")
login_button = dr.find_element_by_css_selector('#loginForm > div > div:nth-child(3) > button')
act = ActionChains(dr)
act.send_keys_to_element(id_box, '아이디').send_keys_to_element(password_box, '비밀번호').click(login_button).perform()
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#react-root > div > div > section > main > div > div > div > div > button')))
#팝업 클릭하기
first_popup = dr.find_element_by_css_selector('#react-root > div > div > section > main > div > div > div > div > button')
first_popup.click()
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'div.RnEpo.Yx5HN > div > div > div > div.mt3GC > button.aOOlW.HoLwm')))
second_popup = dr.find_element_by_css_selector('div.RnEpo.Yx5HN > div > div > div > div.mt3GC > button.aOOlW.HoLwm')
second_popup.click()
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'section > nav > div._8MQSO.Cx7Bp > div > div > div.ctQZg > div > div:nth-child(6) > span')))
#프로필 사진 클릭하기
my_photo = dr.find_element_by_css_selector(
'section > nav > div._8MQSO.Cx7Bp > div > div > div.ctQZg > div > div:nth-child(6) > span')
my_photo.click()
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'section > nav > div._8MQSO.Cx7Bp > div > div > div.ctQZg > div > div:nth-child(6) > div.poA5q > div.uo5MA._2ciX.tWgj8.XWrBI > div._01UL2 > a:nth-child(1) > div')))
#프로필 버튼 클릭하기
profile = dr.find_element_by_css_selector(
'section > nav > div._8MQSO.Cx7Bp > div > div > div.ctQZg > div > div:nth-child(6) > div.poA5q > div.uo5MA._2ciX.tWgj8.XWrBI > div._01UL2 > a:nth-child(1) > div')
profile.click()
wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="react-root"]/div/div/section/main/div/header/div/div/div/button/img')))[ep01:웹크롤링] #12 인스타그램 로그인하기(브라우저 크기 설정/셀레니움) with 파이썬
[왕초보 웹크롤링 따라하기] 웹 제어, 브라우저 크기 설정, 셀레니움, Selenium, 로그인, 텍스트 입력, 클릭, 요소 찾기, 경로 찾기. 업무지옥을 탈출한 건에 대하여(feat.업무자동화) #12 인스타그램
charimlab.tistory.com
2. 스크롤 이동과 상대좌표를 활용하여 전체 피드 확인 코드 작성
상대좌표를 사용하기 위해 크롤링을 시작할 스크롤 위치를 정렬해주고, 상대 좌표의 기준이 될 기준좌표를 설정해 준다. 이 후 각 피드의 범위와 상대좌표를 넣어 동작제어 코드와 스크롤제어 코드를 작성한다.
# 현재 스크롤 위치 정렬
scroll_location = dr.execute_script("return window.pageYOffset")
dr.execute_script("window.scrollTo(0, 479)")
#동작제어 반복코드
while True:
# 로고 좌표 추출
standard_logo = dr.find_element_by_xpath('//section/nav/div[2]/div/div/div[1]/a/div/div')
for line in range(0, 4):
y = 110 + 175 * line # 열 번호를 기준으로 175씩 y좌표를 더함
for box in range(0, 3):
x = 175 * box # 박스 번호를 기준으로 175씩 y좌표를 더함
#피드를 클릭
act = ActionChains(dr)
act.move_to_element(standard_logo).move_by_offset(x, y).click().perform()
WebDriverWait(dr, 10).until(EC.presence_of_element_located((By.XPATH, '//article/div[3]/div[2]/a/time')))
# 게시일자 텍스트 데이터 추출
date = dr.find_element_by_xpath('//article/div[3]/div[2]/a/time').text
print(date)
# 인사이트 열기
dr.find_element_by_xpath('//section[1]/div/button').click()
WebDriverWait(dr, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[9]/div/div/div')))
# 인사이트 닫기
dr.find_elements_by_tag_name('svg')[-1].click()
dr.implicitly_wait(10)
# 피드 닫기
dr.find_element_by_xpath('/html/body/div[6]/div[3]/button/div').click()
# 648 씩 스크롤을 내림
dr.execute_script("window.scrollTo(0,{})".format(scroll_location + 648))
# 전체 스크롤이 늘어날 때까지 대기
dr.implicitly_wait(2)
scroll_height = dr.execute_script("return window.pageYOffset")
# 현재 스크롤 위치와 전체 스크롤 높이가 같으면(더 이상 스크롤이 늘어나지 않으면) 종료
if scroll_location == scroll_height:
break[ep01:웹크롤링] #15 셀레니움 절대좌표/상대좌표 활용하기 with 파이썬
[왕초보 웹크롤링 무작정 따라하기] 웹크롤링, 셀레니움, 절대좌표, 상대좌표, 요소위치 확인, 자바스크립트 사용 업무지옥을 탈출한 건에 대하여(feat.업무자동화) #15 셀레니움 절대좌표/상대
charimlab.tistory.com
[ep01:웹크롤링] #16 셀레니움 스크롤 조절하기 with 파이썬
[왕초보 웹크롤링 따라하기] 웹 제어, 브라우저 크기 설정, 셀레니움, Selenium, 스크롤 내리기, 스크롤 끝까지 내리기, 스크롤 위치 확인, 스크롤 단계별 내리기 업무지옥을 탈출한 건에 대하여(fea
charimlab.tistory.com
3. 데이터 추출 및 오류무시 코드 추가
개발자 도구에서 각 데이터의 경로를 찾아 크롤링 코드를 완성하고, try와 except 코드를 사용해 오류가 발생하지 않도록 해준다. (경로 찾는 과정 생략)
while True:
standard_logo = dr.find_element_by_xpath('//section/nav/div[2]/div/div/div[1]/a/div/div')
try:
for line in range(0, 4):
y = 110 + 175 * line
for box in range(0, 3):
x = 175 * box
#피드를 클릭
act = ActionChains(dr)
act.move_to_element(standard_logo).move_by_offset(x, y).click().perform()
WebDriverWait(dr, 10).until(EC.presence_of_element_located((By.XPATH, '//article/div[3]/div[2]/a/time')))
# 게시일자 텍스트 데이터 추출
date = dr.find_element_by_xpath('//article/div[3]/div[2]/a/time').text
print(date)
# 인사이트 열기
dr.find_element_by_xpath('//section[1]/div/button').click()
WebDriverWait(dr, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[9]/div/div/div')))
# 좋아요, 댓글, 저장
insight = dr.find_elements_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[3]//span')
likes = insight[0].text
print(likes)
comments = insight[1].text
print(comments)
shares = insight[2].text
print(shares)
# 프로필 방문
profile_visits = dr.find_elements_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[5]/div/div/div/div[2]//span')[0].text
print(profile_visits)
# 계정 도달 추정치, 노출, 팔로우
reaching_account = dr.find_element_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[7]/div/div/div/div[2]/div/span[1]').text
print(reaching_account)
total_exposures = dr.find_element_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[7]/div/div/div/div[3]/span[2]').text
print(total_exposures)
gain_follows = dr.find_elements_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[7]/div/div/div//span')[-1].text
print(gain_follows)
# 인사이트 닫기
dr.find_elements_by_tag_name('svg')[-1].click()
dr.implicitly_wait(10)
# 피드 닫기
dr.find_element_by_xpath('/html/body/div[6]/div[3]/button/div').click()
# 스크롤 제어
dr.execute_script("window.scrollTo(0,{})".format(scroll_location + 648))
dr.implicitly_wait(2)
scroll_height = dr.execute_script("return window.pageYOffset")
if scroll_location == scroll_height:
break
else:
scroll_location = dr.execute_script("return window.pageYOffset")
#오류 발생 시, 메세지를 출력하고 코드 종료
except:
print('데이터 수집이 종료되었습니다.')
break[ep01:웹크롤링] #18 오류 무시/예외 처리(Try/Except) with 파이썬
[왕초보 웹크롤링 무작정 따라하기] 웹크롤링, 셀레니움, 오류 무시, 오류 예외 만들기, Try, Except, Exception. 업무지옥을 탈출한 건에 대하여(feat.업무자동화) #18 오류 무시/예외 처리(Try/Except) Try
charimlab.tistory.com
4. 엑셀생성 코드 추가
데이터가 정상적으로 추출되는 것을 확인 했다면, print 코드들을 지우고 엑셀에 추가해 준다. 먼저 크롤링 코드 앞에 엑셀 및 엑셀시트 생성 코드를 작성하고 데이터가 들어갈 columns 리스트를 만들어 준다. 이후 크롤링 코드 내 데이터 추출 마지막 부분에 append 코드를 작성하여 데이터를 엑셀시트에 넣어주면 된다. 마지막으로 엑셀 저장 코드를 작성하여 마무리한다.
# 엑셀 생성
wb = Workbook(write_only=True)
ws = wb.create_sheet('인스타그램 피드 데이터')
columns = ['게시일', '노출', '좋아요', '댓글', '공유','도달계정', '프로필 방문', '획득 팔로우']
ws.append(columns)
# 현재 스크롤 위치 정렬
dr.execute_script("window.scrollTo(0, 479)")
scroll_location = dr.execute_script("return window.pageYOffset")
#크롤링 반복코드
while True:
# 로고 좌표 추출
standard_logo = dr.find_element_by_xpath('//section/nav/div[2]/div/div/div[1]/a/div/div')
try:
for line in range(0, 4):
y = 110 + 175 * line
for box in range(0, 3):
x = 175 * box
#피드를 클릭
act = ActionChains(dr)
act.move_to_element(standard_logo).move_by_offset(x, y).click().perform()
WebDriverWait(dr, 10).until(EC.presence_of_element_located((By.XPATH, '//article/div[3]/div[2]/a/time')))
# 게시일자 텍스트 데이터 추출
date = dr.find_element_by_xpath('//article/div[3]/div[2]/a/time').text
# 인사이트 열기
dr.find_element_by_xpath('//section[1]/div/button').click()
WebDriverWait(dr, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[9]/div/div/div')))
# 좋아요, 댓글, 저장
insight = dr.find_elements_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[3]//span')
likes = insight[0].text
comments = insight[1].text
shares = insight[2].text
# 프로필 방문
profile_visits = dr.find_elements_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[5]/div/div/div/div[2]//span')[0].text
# 계정 도달 추정치, 노출, 팔로우
reaching_account = dr.find_element_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[7]/div/div/div/div[2]/div/span[1]').text
total_exposures = dr.find_element_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[7]/div/div/div/div[3]/span[2]').text
gain_follows = dr.find_elements_by_xpath('/html/body/div[9]/div/div/div/div[2]/div/div/div/div/div/div[7]/div/div/div//span')[-1].text
# 추출
insight_data = [date, total_exposures, likes, comments, shares, reaching_account, profile_visits, gain_follows]
ws.append(insight_data)
# 인사이트 닫기
dr.find_elements_by_tag_name('svg')[-1].click()
dr.implicitly_wait(10)
# 피드 닫기
dr.find_element_by_xpath('/html/body/div[6]/div[3]/button/div').click()
# 스크롤 제어
dr.execute_script("window.scrollTo(0,{})".format(scroll_location + 648))
dr.implicitly_wait(2)
scroll_height = dr.execute_script("return window.pageYOffset")
if scroll_location == scroll_height:
break
else:
# 스크롤 이동 후 스크롤 위치값을 수정
scroll_location = dr.execute_script("return window.pageYOffset")
except:
print('데이터 수집이 종료되었습니다.')
break
#엑셀 저장
wb.save('인스타그램 데이터 크롤링.xlsx')[ep01: 웹크롤링] #7 데이터의 시각화, 엑셀 만들기! with 파이썬
Teaser Copy. 퍼포먼스 마케팅, 그로스해킹, 데이터 측정을 위한 웹 데이터 수집. 파이썬으로 웹 데이터 수집을 자동으로! [왕초보 웹크롤링 따라하기] 데이터 시각화, exel 변환, 파이썬 도표 만들기
charimlab.tistory.com
완성된 코드를 실항하면 아래와 같이 정리된 엑셀을 얻을 수 있다.
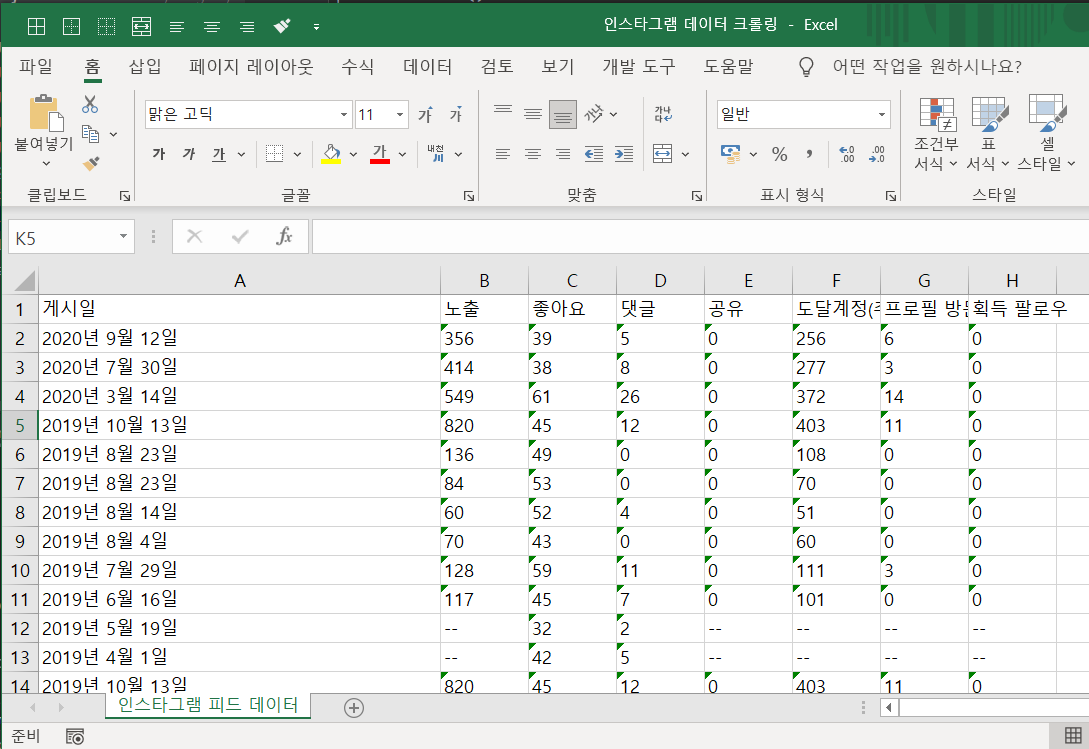
이제 간단한 데이터 리스트업 정도는 자동화 할 수 있게 되었다!
인스타계정 데이터 정도야 피드가 100개건 1000개건 더이상 상관없다. it's easy~
실행시켜두고 몇 분이면 끝나니까. 이 것이 웹크롤링이닷!!!

[System] 승급에 성공하였습니다.
현재 클래스 : Class 3
새로운 칭호를 획득하였습니다.
'칭호: 데이터 정복자'
[보유 스킬]
오류처리, 동작제어, 자바스크립트 활용,
주문가속, 주문중첩, 주문연계,
데이터시각화, 데이터필터링, 웹데이터 소환
[보유 칭호]
데이터 정복자, 브라우저를 제어하는 자,
웹데이터를 불러내는 자
'데이터 스킬업 > 웹크롤링' 카테고리의 다른 글
| [파이썬: 웹크롤링] #07 원하는 데이터 추출하기 with 리스트 슬라이싱/for문/if 조건문 (0) | 2022.03.26 |
|---|---|
| [파이썬:웹크롤링] #20 셀레니움과 input으로 로그인 하기 for 인스타그램 (0) | 2022.01.16 |
| [ep01:웹크롤링] #18 오류 무시/예외 처리(Try/Except) with 파이썬 (0) | 2021.08.12 |
| [ep01:웹크롤링] #17 셀레니움 로딩될 때까지 시간/조건 설정하기 with 파이썬 (1) | 2021.08.05 |
| [ep01:웹크롤링] #16 셀레니움 스크롤 조절하기 with 파이썬 (0) | 2021.08.03 |
댓글