[왕초보 웹크롤링 무작정 따라하기] 파이썬 반복문(for문/폴문), 리스트(list), 리스트 슬라이싱, 홀수/짝수 제거. 불린함수, if함수
#07 원하는 데이터 추출하기
1. 리스트 슬라이싱으로 홀수/짝수 제거 (바로가기 click)
2. for문과 if조건으로 홀수/작수 제거 (바로가기 click)
이전의 쳅터에서는 .find()를 사용해 class의 유무로 필요한 데이터를 추출했다. 하지만, 이전의 경우는 운이 좋았을 뿐 필요한 데이터와 불필요한 데이터의 경로가 동일하고 class가 같거나 없을 때는 둘을 구분할 수 없게 된다. 이럴 때는 리스트 슬라이싱과 if문을 사용하여 원하는 데이터만 필터링할 수 있다.
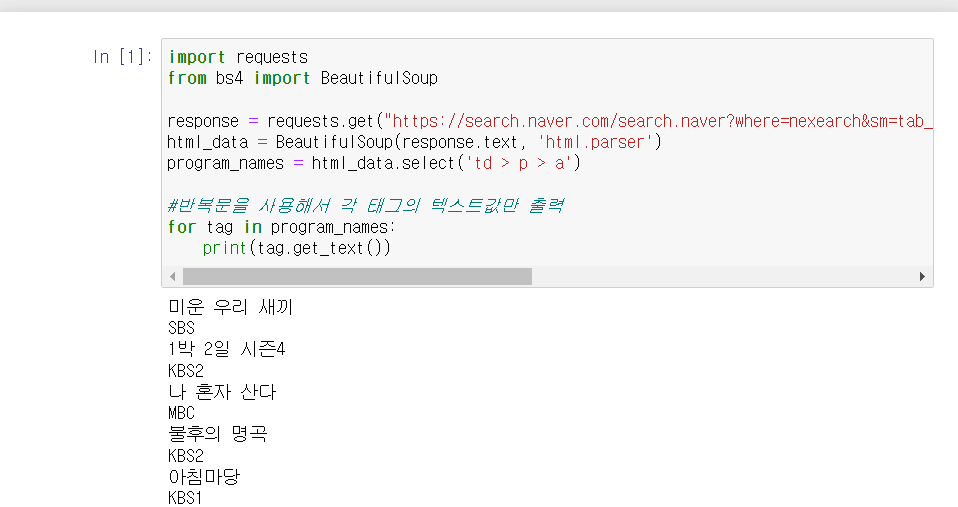
프로그램명과 채널명이 함께 추출되었던 것을 확인해면 홀수 번째 요소는 '채널', 짝수 번째 요소는 '프로그램명'인 것을 알 수 있다. 즉, 필요없는 데이터인 짝수 번째 요소를 제거하면 '프로그램명'만 추출할 수 있는 것이다.
리스트 슬라이싱으로 홀수/짝수 제거하기
리스트 슬라이싱은 [리스트]를 특정한 기준으로 쪼개는 것으로 각 요소의 번호표라고 할 수 있는 '인덱스'를 기준으로 삼는다. 인덱스로는 눈으로도 파악할 수 있고, .index()메소드를 사용해서 확인할 수도 있다.예를 들어, [a, l, p, h, a, b, e, t]이라는 리스트가 있을 때, 요소 'a'의 인덱스는 '0'이고 alphabet.index('a')로도 확인할 수 있다. print(alphabet.index('a')) 해보면 0이 출력된다.
| alphabet = ['a', 'b', 'c', 'd', 'e', 'f'] | |
| 첫번째 요소 = 'a' | 인덱스 0 |
| 두번째 요소 = 'b' | 인덱스 1 |
| ... | |
alphabet = ['a', 'b', 'c', 'd', 'e', 'f']를 슬라이싱하면 ['a', 'b', 'c'] 또는 ['a', 'c', 'e'] 또는 ['b', 'd', 'f'] 등 다양한 방식으로 분리할 수 있다. 리스트의 슬라이싱은 list[시작 인덱스 : 마지막 인덱스 : 간격]의 형식이며 숫자 0은 생략할 수 있다.
| alphabet[:3] | 0번 인덱스 부터 2번 인덱스 뽑아낸다. | ['a', 'b', 'c'] |
| alphabet[3:] | 3번 인덱스 부터 마지막 인덱스까지 뽑아낸다. | ['d', 'e', 'f'] |
| alphabet[2:4] | 번 인덱스 부터 3번 인덱스까지 뽑아낸다. | ['c', 'd'] |
| alphabet[::2] | 0번 인덱스부터 마지막 인덱스까지 2개씩 건너 뛴 인덱스를 뽑아낸다. *홀수 번째 인덱스를 뽑아내는데 사용 |
['a', 'c', 'e'] |
| alphabet[1::2] | 1번 인덱스부터 마지막 인덱스까지 2개씩 건너 뛴 인덱스를 뽑아낸다. *짝수 번째 인덱스를 뽑아내는데 사용 |
['b', 'd', 'f'] |
인덱스에 대해 알아봤으니 리스트인 'program_names'를 [::2]로 슬라이싱 하여 짝수 인덱스에 있는 '프로그램명'만 뽑아보자.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver?where=nexearch&sm=tab_etc&mra=blUw&qvt=0&query=%EC%A3%BC%EA%B0%84%EC%98%88%EB%8A%A5%20%EC%8B%9C%EC%B2%AD%EB%A5%A0")
html_data = BeautifulSoup(response.text, 'html.parser')
program_names = html_data.select('td > p > a')
#슬라이싱으로 홀수 번째 인덱스만 추출
program_names = program_names[::2]
for tag in program_names:
print(tag.get_text())
for문과 if조건으로 홀수/짝수 제거하기
두번째 방법으로 for문과 if조건을 사용해보자. 우선 for문의 작동원리를 살펴보자. 앞서 작성한 for문은 리스트인 Program_name의 각 요소<tag>들의 텍스트만 print()해주는 식으로 더이상 실행시킬 요소가 없을 때까지 반복한다.
| Program_name = ['<a~></a>', ~~~] for tag in Program_name: text값만 출력(print) |
|||
| 1회 시행 | 첫번째 요소의 text값만 print | 미운 우리 새끼 | |
| 2회 | 두번째 요소의 text값만 print | SBS | |
| ...(반복)... | 순차적으로 반복 | 궁금한 이야기 Y, SBS | |
| 마지막 | 마지막 요소의 text값만 print | ... | |
마찬가지로 '프로그램명' 데이터만 추출하려면 for문에서도 홀수 번째 요소만 text값을 출력하도록 조건을 추가해 한다. 이때 for문 안에 if문을 추가하여 반복해서 요소가 홀수일 때 텍스트를 추출하고, 짝수일 때 추출하지 않고 넘어가는 코드를 넣는 것이다. if문은 기본적으로 참일 때와 거짓일 때의 수행동작을 다르게 설명할 수 있다. 기존 for문에 홀수 번째 요소만 출력하는 if문의 처리 과정은 아래와 같다.
| Program_name = ['<a~></a>', ~~~] for tag in Program_name: tag가 홀수 번째 일때 text값만 출력 |
||||
| 1회 시행 | 첫번째(홀수) 요소일 때, (참) | text값만 print | 미운 우리 새끼 | |
| 2회 | 두번째(짝수) 요소일 때, (거짓) | 위 조건이 거짓이므로 수행X | ||
| ...(반복)... | 순차적으로 반복 | 궁금한 이야기 Y, ... | ||
우리는 기존의 코드에서 홀수 번째일때만 다음 작업을 수행하게 해야한다. 앞서 설명했듯 홀수 번째 요소는 짝수 인덱스를 갖기 때문에 지금 구해야할 인덱스 짝수이다. 짝수/홀수를 간단한 수학식으로 만들어 보자.
| 홀수 | n%2 == 1 | 숫자(n)를 2로 나눴을 때 나머지(%2)가 1이면 홀수 |
| 짝수 | n%2 == 0 | 숫자(n)를 2로 나눴을 때 나머지(%2)가 0이면 짝수 |
'요소(tag)의 인덱스 번호를 2로 나눠 나머지가 0'일때 다음 동작을 수행하는 if문을 만들어야한다. 식으로 나타내면 if program_name.index(tag) % 2 == 0: 이다. 기존 코드에 추가해 주자.
import requests
from bs4 import BeautifulSoup
response = requests.get("https ~ ")
html_data = BeautifulSoup(response.text, 'html.parser')
program_name = html_data.select('td>p>a')
for tag in program_nam: # [리스트] program_name의 각 요소(tag)들을 조건에 맞춰 반복 실행
if program_name.index(tag) % 2 == 0: # 조건01: 요소의 인덱스를 2로 나누었을 때 0이 남으면 (=인덱스가 짝수일때)
print(tag.get_text()) # 조건02: 요소 tag의 데이터에서 text값만 출력
구동 원리를 살펴보면 1차 실행에서 요소의 인덱스는 0이고, 2로 나누었을 때 0(짝수)이므로 text값을 출력한다. 2차 실행에선 요소의 인덱스가 1이고 2로 나누었을 때 1(홀수)이므로 text가 출력되지 않는다. 이런 조건을 반복하게 되면 짝수 인덱스의 tag값에만 print()가 동작하여 '프로그램명'만 출력할 수 있다.
| Program_name = ['<a~></a>', ~~~] for tag in Program_name: if program_name.index(tag) % 2 == 0 #tag의 인덱스 번호가 짝수 일때, 아래 동작을 수행 print(tag.get_text()) #text값만 출력 |
||||
| 1회 시행 | if program_name.index(첫번째 요소) % 2 == 0 *인덱스 '0' 나누기 '2'는 나머지가 '0' (참) |
print(tag.get_text()) | 미운 우리 새끼 | |
| 2회 | if program_name.index(두번째 요소) % 2 == 0 *인덱스 '1' 나누기 '2'는 나머지가 '1' (거짓) |
위 조건이 거짓이므로 수행X |
||
| ...(반복)... | 순차적으로 반복 | 궁금한 이야기 Y, ... | ||
다양한 방법으로 목표한 '프로그램명' 데이터를 뽑아봤다. 하나의 결과를 도출하는데 다양한 방법이 있지만
코드를 짤때는 가장 간단한 방법을 사용하는 것이 좋다. 이번 경우에는 슬라이싱이 가장 간단하다. 이제 슬라이싱을 사용한 코드를 바탕으로 데이터 표까지 만들어 보자.
▼다음편 이어보기▼
[ep01: 웹크롤링] #08 데이터의 시각화, 엑셀 만들기! with 파이썬
[왕초보 웹크롤링 따라하기] 데이터 시각화, exel 변환, 파이썬 도표 만들기, openpyxl, Workbook 업무지옥을 탈출한 건에 대하여(feat.업무자동화) #08 데이터의 시각화, 엑셀 만들기! with 파이썬 이번
charimlab.tistory.com
'데이터 스킬업 > 웹크롤링' 카테고리의 다른 글
| [파이썬: 웹크롤링] #09 리스트로 데이터프레임(DataFrame) 만들기 with Pandas (0) | 2022.06.12 |
|---|---|
| [파이썬: 웹크롤링] #08 데이터의 시각화, 엑셀 만들기! with openpyxl (0) | 2022.06.12 |
| [파이썬:웹크롤링] #20 셀레니움과 input으로 로그인 하기 for 인스타그램 (0) | 2022.01.16 |
| [ep01:웹크롤링] #19 인스타그램 웹크롤링 자동화(예제) with 파이썬 (1) | 2021.08.13 |
| [ep01:웹크롤링] #18 오류 무시/예외 처리(Try/Except) with 파이썬 (0) | 2021.08.12 |
댓글