[왕초보 웹크롤링 따라하기] 데이터 시각화, 파이썬 도표 만들기, 판다스(pandas), 데이터프레임(Dataframe), 리스트
#09 리스트로 표(DataFrame) 만들기
엑셀로 데이터를 보는 것이 익숙하긴 하지만, 크롤링한 데이터를 엑셀로 보는 것은 추가로 작성해야하는 코드도 많고 엑셀을 켜야하는 등 상당히 번거로울 수 있다. 이번에는 코딩창에서 표를 바로 볼 수 있는 방법을 알아보자.
판다스(pandas) 모듈 사용하기
pandas 모듈은 리스트 데이터를 데이터프레임(표)을 만들어 주는 모듈이다. Terminal 창에 pip install pandas를 적어 설치하고 코드창에 import 해주자. 이제 이전에 작성한 엑셀 관련 코드를 모두 지우고 [리스트]를 데이터프레임(df)으로 바꿔줘야한다.
import requests
from bs4 import BeautifulSoup
import pandas as pd #pandas 모듈 추가
response = requests.get("https://search.naver.com/search.naver?where=nexearch&sm=tab_etc&mra=blUw&qvt=0&query=05월31일주%20예능%20시청률")
html_data = BeautifulSoup(response.text, 'html.parser')
program_names = html_data.select('td>p>a')
program_name = program_names[::2]
ranking = 0
for tag in program_name:
ranking = ranking + 1
name = tag.get_text()
row = [ranking, name]
엑셀의 워크시트가 빈 리스트의 역할을 해주었던 것처럼 판다스를 사용할 때도 빈 리스트가 필요하다. 엑셀을 만들 때는 column을 먼저 지정하고 row값을 입력해 줬지만 판다스는 반대다. 판다스를 사용할 때는 row값을 먼저 뽑아두고 마지막에 column을 지정해준다. 그리고 워크시트가 빈 리스트 였던 것과 같이 for문을 시작하기 전에 빈 리스트 rows를 만들어준다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
response = requests.get("https://search.naver.com/search.naver?where=nexearch&sm=tab_etc&mra=blUw&qvt=0&query=05월31일주%20예능%20시청률")
html_data = BeautifulSoup(response.text, 'html.parser')
program_names = html_data.select('td>p>a')
program_name = program_names[::2]
rows = [] #빈 리스트 만들기
ranking = 0
for tag in program_name:
ranking = ranking + 1
name = tag.get_text()
row = [ranking, name] #for문으로 추출한 '순위'와 '프로그램명'을 묶음
rows.append(row) #추출한 '순위'와 '프로그램명'을 묶음을 rows 리스트에 추가
print(rows)로 확인해보면 [[1, '미운 우리 새끼'], [2, '궁금한 이야기 Y'], [3, '1박 2일 시즌4'], ...]로 '순위'와 '프로그램명'이 한 쌍으로 묶인 것을 볼 수 있다. 컬럼과 로우에 대한 리스트와 데이터프레임의 관계는 아래와 같다.
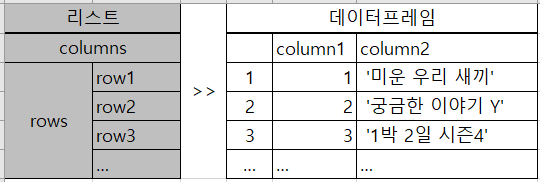
row값들은 채웠고, 이제 column값들을 지정해 줘야 한다. 데이터프레임을 만드는 식은 pd.DataFrame(rows, columns=['순위', '프로그램명'])로 괄호 앞에 추출한 로우 리스트를, 뒤에 columns=[ ]를 적어 지정해 준다. rmflrh print(df)로 만들어진 데이터프레임을 출력하면 완성된 데이터프레임을 볼 수 있다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
response = requests.get("https://search.naver.com/search.naver?where=nexearch&sm=tab_etc&mra=blUw&qvt=0&query=05월31일주%20예능%20시청률")
html_data = BeautifulSoup(response.text, 'html.parser')
program_names = html_data.select('td>p>a')
program_name = program_names[::2]
#빈 리스트 만들기
rows = []
ranking = 0
for tag in program_name:
ranking = ranking + 1
name = tag.get_text()
row = [ranking, name]
rows.append(row)
df = pd.DataFrame(rows, columns = ['순위', '프로그램명'])
print(df)
▼다음편 이어보기▼
[ep01: 웹크롤링] #9 데이터 시각화 최고효율, 쥬피터노트북 with 파이썬
Teaser Copy. 퍼포먼스 마케팅, 그로스해킹, 데이터 측정을 위한 웹 데이터 수집. 파이썬으로 웹 데이터 수집을 자동으로! [왕초보 웹크롤링 따라하기] 데이터 시각화, 파이썬 도표 만들기, 판다스(
charimlab.tistory.com
'데이터 스킬업 > 웹크롤링' 카테고리의 다른 글
| [파이썬:웹크롤링] #11 쇼핑몰 제품정보/평점/리뷰수 리스트업 (0) | 2022.06.12 |
|---|---|
| [파이썬:웹크롤링] #10 쥬피터노트북 dataframe 만들기 with Pandas (0) | 2022.06.12 |
| [파이썬: 웹크롤링] #08 데이터의 시각화, 엑셀 만들기! with openpyxl (0) | 2022.06.12 |
| [파이썬: 웹크롤링] #07 원하는 데이터 추출하기 with 리스트 슬라이싱/for문/if 조건문 (0) | 2022.03.26 |
| [파이썬:웹크롤링] #20 셀레니움과 input으로 로그인 하기 for 인스타그램 (0) | 2022.01.16 |
댓글